Entity Match & Merge - InsideView
About InsideView: InsideView is a software as a service (SaaS) company that gathers insights and relationships to provide analytics on marketing to customers. Founded in 2005, InsideView is mainly used by marketing, sales, and operations teams in identifying and gathering information on customers and prospects. In April 2021, the company was acquired by Demandbase, Inc.
1. Context and Background: During the period of 2006-2008, the B2B SaaS landscape was still in its early stages, with Salesforce (SFDC) emerging as a key player, both from a technical and business model perspective. At that time, the traditional sales model, which relied heavily on cold calls, was outdated and inefficient. With SFDC offering a revolutionary CRM platform to manage customer relationships, including leads, opportunities, and prospects, the market was primed for disruption. InsideView identified an opportunity to revolutionize the sales process by leveraging data and information to transition from cold calls to warm calls, thereby shortening sales cycles and improving efficiency.
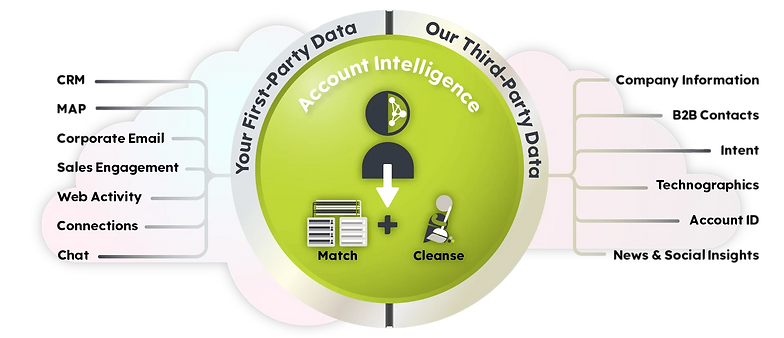
2. The Problem: InsideView’s product aggregated vast amounts of information about companies and executives from over 40,000 different sources, including more than 20 sources specifically for company and executive data, with the remaining sources providing news and other relevant information. The challenge lay in managing this vast data pool. Specifically, InsideView faced two significant challenges:
-
Entity Matching: When the same company appeared across multiple data sources, how could we accurately match them to confirm they were indeed the same entity?
-
Data Reliability: Once matched, how could we determine which data points (e.g., name, address, revenues, employee numbers) were the most reliable and should be displayed?
3. The Product: InsideView developed a sophisticated product that provided users with a single, unified company entity, despite the complex backend processes required to achieve this. The core components of the product were:
-
Matcher Algorithm: Over the course of eight years, we iterated through three versions of the matcher, which utilized advanced deduplication techniques and machine learning algorithms to match company entities across different data sources.
-
Triangulation Algorithm: This algorithm, which also evolved through five versions over the same period, was designed to select the most reliable data for each entity by considering various parameters such as source priority, data freshness, automated validation, and source accuracy relative to company size.
4. My Role: I initially joined InsideView in a Data Engineering role, where I was responsible for analyzing data and developing the algorithms for entity matching and triangulation. As the project evolved, I transitioned into a Product Management role, overseeing the entire platform. My responsibilities included scaling the system, continuously improving the algorithms to enhance precision and recall, and introducing features like manual override functions that allowed users to correct information errors. Additionally, I played a key role in building an engaged community that actively reported any data discrepancies, further improving the system’s accuracy. In the third version of the matcher, we implemented an active learning model, enabling the algorithm to self-correct by automatically incorporating feedback from identified errors, thereby enhancing the accuracy of the unsupervised machine learning model.
5. Technical Stack: The initial versions of the matcher were developed using Java, with data stored in MySQL. As the system scaled, we transitioned to Python, with data being processed in Amazon RDS and Redshift. The machine learning models employed included a diverse ensemble, featuring Logistic Regression, Support Vector Machines (SVM), Random Forests, Decision Trees, and Neural Networks.
6. Impact: When I first joined InsideView, the initial version of our product had a Data Accuracy Score of 0.6. By the time I left, we had achieved an industry-leading accuracy score of over 0.9. This dramatic improvement had a significant impact on our customers, who now had access to a highly accurate, unified data entity enriched with information from multiple sources, positioning it as their source of truth. The product became a cornerstone of InsideView’s offering, contributing $35 million in annual revenue by the time the company was acquired by DemandBase.
Conclusion:
The Entity Match and Merge project at InsideView is a prime example of how leveraging advanced data science techniques, combined with a deep understanding of market needs, can lead to significant improvements in product performance and customer satisfaction. Through continuous iteration and a focus on precision, we were able to create a product that not only solved complex data challenges but also drove substantial business value, ultimately contributing to InsideView’s successful acquisition.
More about this Product here.